Production Quality Evaluations
This is step 5 of the tutorial. If you missed the previous parts, start here
Overview
So far, a fairly robust delivery pipeline has been built. Optional manual approval steps have been added, automated quality gates were then added to automate and improve on the previous manual approval. Finally, release validation was added to run quality evaluations after a production release and ensure quality software in production.
This step adds the ability to Keptn to self-heal your application based on problems sent to Keptn.
Scenario
Imagine the applicaiton has a known response time problem in production. It can be fixed by scaling the pods - at least until development has a chance to look into the issue.
We will add steps into our Keptn setup to:
- Scale the pods (using Helm to upgrade the deployment) when a response time problem is received.
- Use
locustto generate some new load after the deployment has been scaled - Run a quality evaluation to see if the scaling has resolved the issue
Note: The demo image doesn’t actually have a problem pattern that resolves with scaling. So expect the quality gate to still provide a warning. Scaling the pods will be successful.
Add New Sequence to Shipyard
Modify the shipyard in the main branch of the Git upstream. Add a new sequence in production which will be triggered when a problem is received.
This sequence will recursively self-trigger every 2 minutes until the evaluation is in a pass or warning state. This allows for escalating self-healing actions.
Add this block to the production stage:
- name: "remediation"
triggeredOn:
- event: "production.remediation.finished"
selector:
match:
evaluation.result: "fail"
tasks:
- name: "get-action"
- name: "action"
- name: "je-test"
- name: "evaluation"
properties:
timeframe: "2m"
The shipyard.yaml file should now look like this:
apiVersion: "spec.keptn.sh/0.2.2"
kind: "Shipyard"
metadata:
name: "shipyard-delivery"
spec:
stages:
- name: "qa"
sequences:
- name: "delivery"
tasks:
- name: "je-deployment"
- name: "je-test"
- name: "evaluation"
properties:
timeframe: "2m"
- name: "production"
sequences:
- name: "delivery"
triggeredOn:
- event: "qa.delivery.finished"
tasks:
- name: "approval"
properties:
pass: "automatic"
warning: "automatic"
- name: "je-deployment"
- name: "je-test"
- name: "evaluation"
properties:
timeframe: "2m"
- name: "remediation"
triggeredOn:
- event: "production.remediation.finished"
selector:
match:
evaluation.result: "fail"
tasks:
- name: "get-action"
- name: "action"
- name: "je-test"
- name: "evaluation"
properties:
timeframe: "2m"
Explanation
The remediation sequence:
- Is triggered when a problem is sent to Keptn (you’ll see this soon)
get-actionretrieves the self-healing action from theremediation.yamlfile (this will be created soon)actionuses the job executor service andhelmto scale thereplicaCountof the deployment- After scaling, job executor service again responds to
je-testand useslocustto generate some load - A quality gate evaluation is executed to validate whether or not the scaling actually helped to resolve the issue (expect this to say
warning) - If the quality gate fails, the sequence will be recursively called every 2 minutes until the evaluation fails.
Create Remediation File
This file maps an incoming problem to the healing action that should occur.
For simplicity we have only one action, but multiple actions per problem type are possible. Keptn will try them in order, which means you can try less invasive resolutions first, escalating them if they fail.
The important parts here are problemType denotes the name of the problem type we are expecting to be sent (from an external feed or observability platform). The action denotes what we do when this problem type is received and the value will be used to tell helm how many replicas are required in the new deployment.
cat << EOF > helloservice-remediation.yaml
apiVersion: spec.keptn.sh/0.1.4
kind: Remediation
metadata:
name: helloservice-remediation
spec:
remediations:
- problemType: http_response_time_seconds_main_page_sum
actionsOnOpen:
- action: scale
name: scale
description: Scale up
value: "2"
EOF
Add this file to the Git upstream directly or use the keptn add-resource helper command to upload it for you.
Notice that it is stored in Git as remediation.yaml and not as it is called on disk: helloservice-remediation.yaml. The filename is important and expected to be remediation.yaml.
keptn add-resource --project=fulltour --stage=production --service=helloservice --resource=helloservice-remediation.yaml --resourceUri=remediation.yaml
Link Input to Action
Keptn now knows what it should attempt to do, but recall that Keptn itself doesn’t actually perform the actions. We need to bring a tool. We choose to use the job executor service which in turn will use helm to scale the deployment.
On the production branch of your Git upstream, modify helloservice/job/config.yaml and add a new action:
- name: "Remediation: Scaling with Helm"
events:
- name: "sh.keptn.event.action.triggered"
jsonpath:
property: "$.data.action.action"
match: "scale"
tasks:
- name: "Scale with Helm"
files:
- /charts
env:
- name: REPLICA_COUNT
value: "$.data.action.value"
valueFrom: event
image: "alpine/helm:3.9.0"
serviceAccount: "jes-deploy-using-helm"
cmd: ["helm"]
args: ["upgrade", "-n", "$(KEPTN_PROJECT)-$(KEPTN_STAGE)", "$(KEPTN_SERVICE)", "/keptn/charts/$(KEPTN_SERVICE).tgz", "--set", "replicaCount=$(REPLICA_COUNT)"]
Your job/config.yaml should now look like this:
apiVersion: v2
actions:
- name: "Deploy using helm"
events:
- name: "sh.keptn.event.je-deployment.triggered"
tasks:
- name: "Run helm"
files:
- /charts
env:
- name: IMAGE
value: "$.data.configurationChange.values.image"
valueFrom: event
image: "alpine/helm:3.9.0"
serviceAccount: "jes-deploy-using-helm"
cmd: ["helm"]
args: ["upgrade", "--create-namespace", "--install", "-n", "$(KEPTN_PROJECT)-$(KEPTN_STAGE)", "$(KEPTN_SERVICE)", "/keptn/charts/$(KEPTN_SERVICE).tgz", "--set", "image=$(IMAGE)", "--wait"]
- name: "Run tests using locust"
events:
- name: "sh.keptn.event.je-test.triggered"
tasks:
- name: "Run locust"
files:
- locust/basic.py
- locust/locust.conf
image: "locustio/locust:2.8.6"
cmd: ["locust"]
args: ["--config", "/keptn/locust/locust.conf", "-f", "/keptn/locust/basic.py", "--host", "http://$(KEPTN_SERVICE).$(KEPTN_PROJECT)-$(KEPTN_STAGE)", "--only-summary"]
- name: "Remediation: Scaling with Helm"
events:
- name: "sh.keptn.event.action.triggered"
jsonpath:
property: "$.data.action.action"
match: "scale"
tasks:
- name: "Scale with Helm"
files:
- /charts
env:
- name: REPLICA_COUNT
value: "$.data.action.value"
valueFrom: event
image: "alpine/helm:3.9.0"
serviceAccount: "jes-deploy-using-helm"
cmd: ["helm"]
args: ["upgrade", "-n", "$(KEPTN_PROJECT)-$(KEPTN_STAGE)", "$(KEPTN_SERVICE)", "/keptn/charts/$(KEPTN_SERVICE).tgz", "--set", "replicaCount=$(REPLICA_COUNT)"]
Explanation
The new task:
- Listens for the
action.triggeredevent when the JSON payload contains anactionword ofscale(this references theactionfield inremediation.yaml) - Retrieves the replica count from the incoming JSON payload (this references the
valuefield inremediation.yaml) - Uses
helmto upgrade thehelloservice.tgzhelm chart and sets thereplicaCountto whatever value is specified inremediation.yaml(in our case2)
Subscribe Job Executor Service to the Action
We have all the important parts now in place but we’re missing one final piece. The job executor service needs to listen for the action.triggered event so it knows to start when a remediation action is successfully detected.
In the Keptn’s bridge, add a new subscription for the JES to action.triggered.
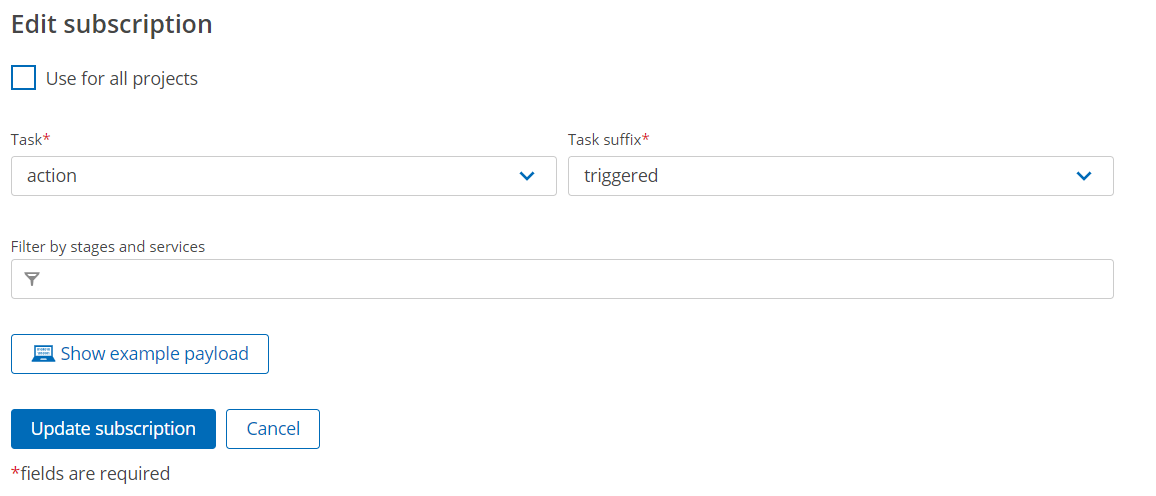
The job executor service subscriptions should now look like this:

Create a fake problem
In reality you would rely on prometheus alert manager or another incoming problem feed from an external observability platform.
For our demo though, we can “fake” this payload so you can easily and quickly retrigger:
cat <<EOF > remediation_trigger.json
{
"type": "sh.keptn.event.production.remediation.triggered",
"specversion": "1.0",
"source": "https://github.com/keptn/keptn/fake-problem",
"contenttype": "application/json",
"data": {
"project": "fulltour",
"stage": "production",
"service": "helloservice",
"problem": {
"problemTitle": "http_response_time_seconds_main_page_sum"
}
}
}
EOF
Notice two important details:
- The
typeisproduction.remediation.triggered. We are telling Keptn totriggertheremediationsequence in theproductionstage - The
problemTitleishttp_response_time_seconds_main_page_sum. This matches what is in theremediation.yamlfile
Trigger a Problem
Send Keptn a problem event and watch Keptn scale the pods:
keptn send event -f remediation_trigger.json
When the sequence is complete, you should see:
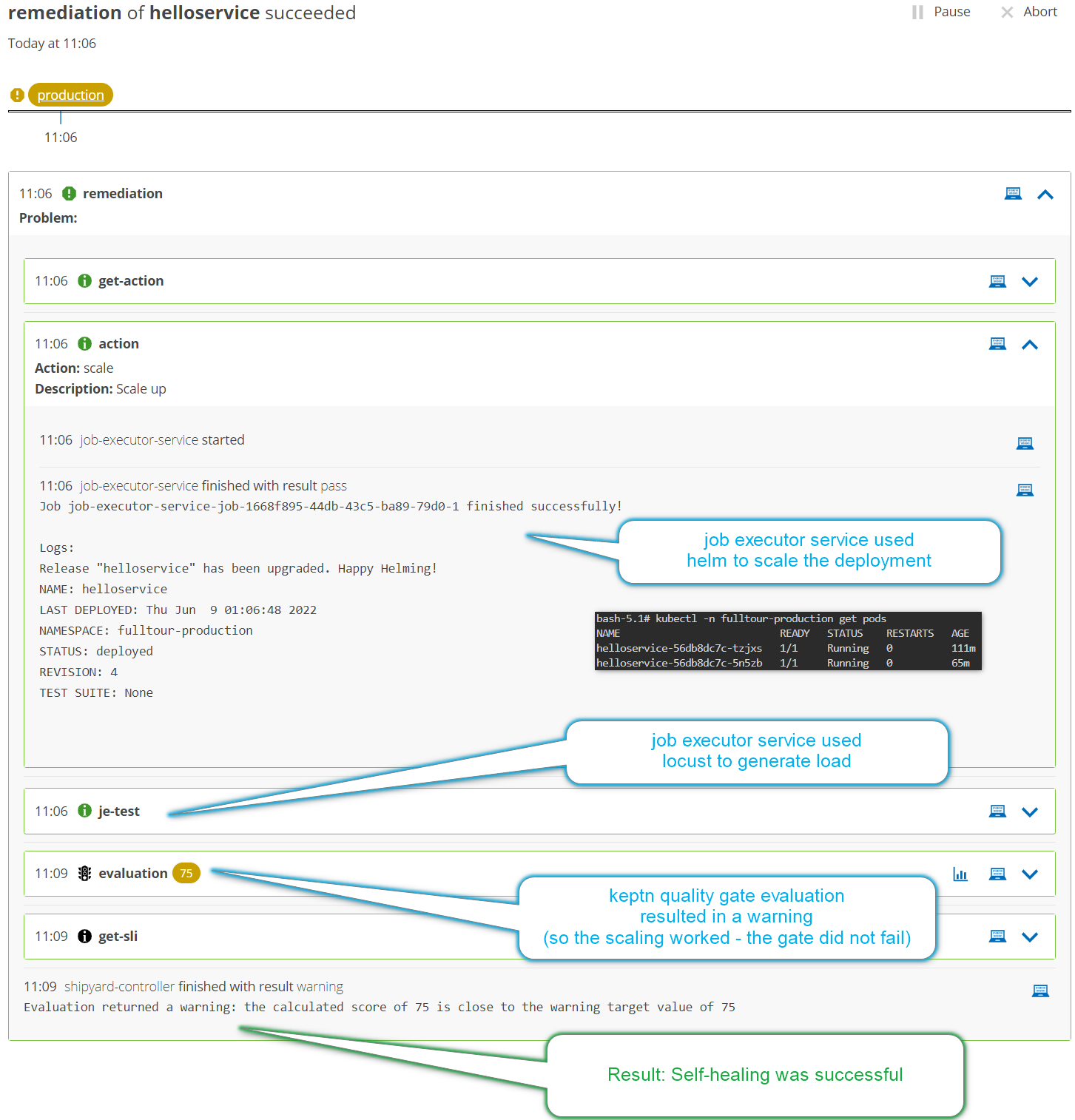
🎉 Congratulations 🎉
You have used Keptn to build a fortified end-to-end delivery orchestration whilst avoiding tool and vendor lock in. The delivery orchestration you have build:
- Uses the tooling you like
- Prevents bad code, automatically stopping deployments if quality checks fail.
- Can accomodate manual approvals if required
- Can self-heal by taking actions in production, again using the tooling you want
Cleanup
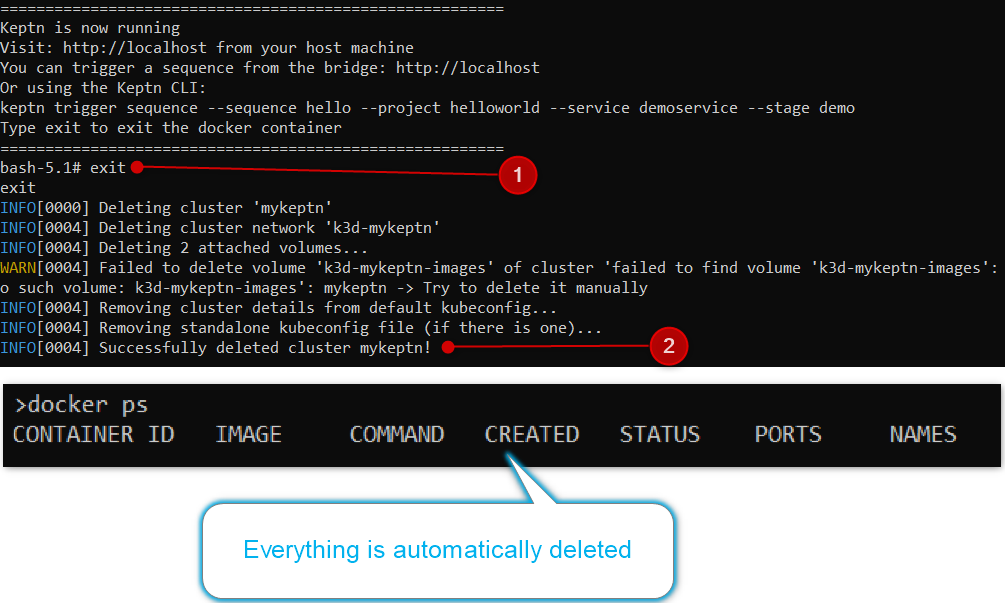
Open the terminal window (not the web terminal) where you originally executed the docker run command.
Type exit and everything will be automatically deleted for you.
So What’s Next?
Deploy Keptn properly on your cluster to free your SRE and DevOps teams from toil. Star Keptn on GitHub
Need help? Ask in the Keptn Slack channel
Found a bug or issue? Create an issue on GitHub
It is almost guaranteed that Keptn works with your tool. Want to know if someone has gone before you? See all publicly documented integrations here.
Want to suggest (or submit) a new tooling integration that Keptn could / should work with? Ask for it or submit it here.